前言
在学习大模型训练库unsloth时看到和FlashAttention的对比,因为之前也听说过,感觉这个技术还挺火的,所以趁这个机会研究一下。
现今的模型基本上基于transformer,模型变的越来越大,越来越深,但是扩展序列长度却还是很困难。因为其核心自注意力模块的内存和时间复杂度对于序列长度是平方级别的。
在FlashAttention之前,业界的主流方案是减少计算量,而没有关注内存的访问成本。现今的显卡的计算速度已经远超内存速度,内存访问已经成为瓶颈。FlashAttention通过减少显存数据的读写量,提高了数据的吞吐量,从而提升速度并节省了内存。
FlashAttention
架构
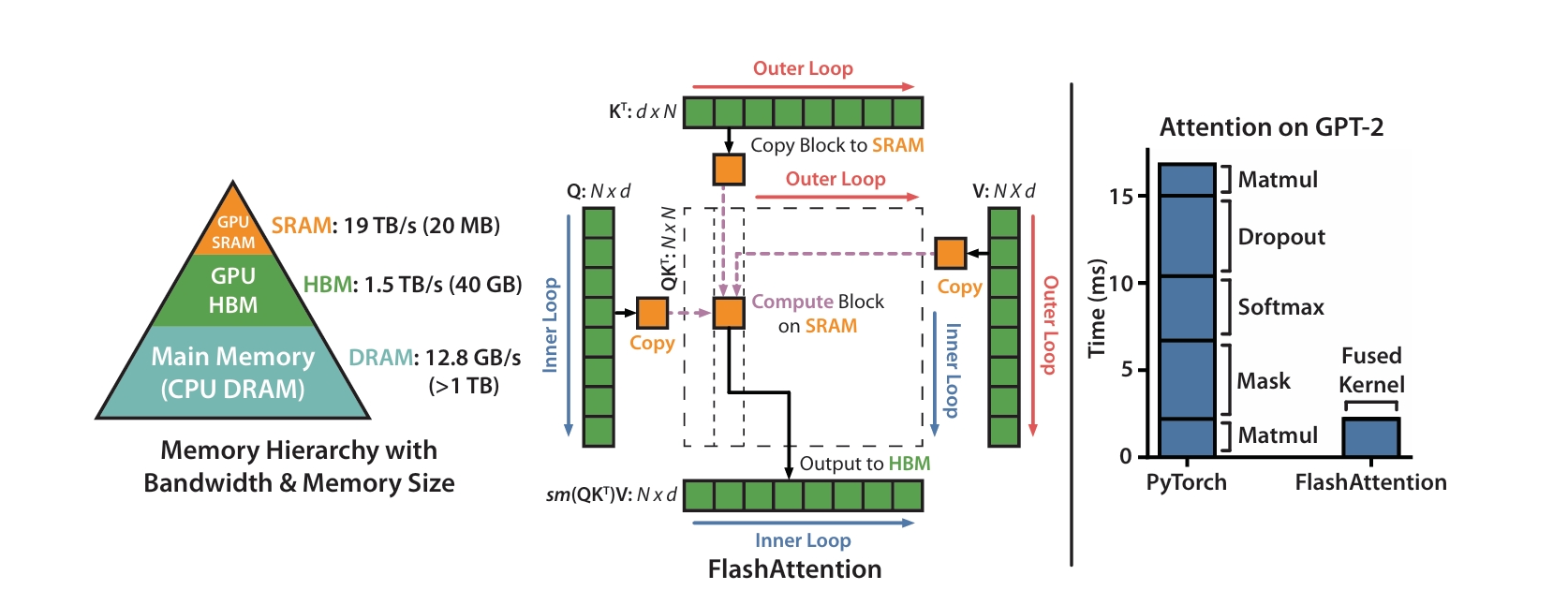
FlashAttention主要使用以下两个技巧:分片计算和重计算。分片计算是指对矩阵进行分片,实现了softmax的分片计算,在前向和后向传播中都使用了分片计算,它使分片后的数据大小能够适应共享内存。重计算是指在前向传播减少存储的数据,在反向传播时计算原先需要的数据。两者的目的都是减少高速内存的访问,尽可能利用共享内存提速。
性能
根据官方提供的数据,和原始Pytorch版本相比,在训练上,FlashAttention的速度至少提升了2倍,FlashAttention2的速度至少提升了3倍。内存减少量随着序列长度线性增长,当序列长度为2k时,内存减少了10倍,当序列长度为4k时,减少了20倍,这个结果说明FlashAttention能使用更长的序列长度。
分片计算
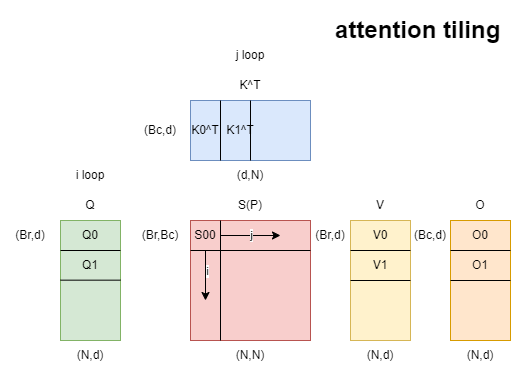
首先为了数值稳定性,引入safe softmax。定义softmax的向量x∈RB,公式如下:
m(x)=max(xi),f(x)=[ex1−m(x)...exB−m(x)],l(x)=i∑f(x)i,softmax(x)=l(x)f(x)
safe softmax的标准实现:
for i = 1, N do
mi=max(xi−1,xi)
end
for i = 1, N do
li=li−1+exi−mN
end
for i = 1, N do
p=softmax(x)=lNexi−mN
end
我们可以看到标准实现使用了三重循环,效率太低。我们可以通过实现softmax的分片计算,实现迭代,减少循环次数。
li=j=1∑iexj−mi=(j=1∑i−1exj−mi)+exi−mi=(j=1∑i−1exj−mi−1)emi−1−mi+exi−mi=li−1emi−1−mi+exi−mi
优化后从三重循环变成双重训练。
for i = 1, N do
mili=max(xi−1,xi)=li−1emi−1−mi+exi−mi
end
for i = 1, N do
pi=softmax(x)=lNexi−mN
end
接下来再看注意力公式,能否将循环次数优化到一次。(为了方便理解,忽略了缩放系数√d1)
S=QKT∈RN×N,P=softmax(S)∈RN×N,O=PV∈RN×d
设Q[k,:]为Q矩阵的第k行向量,KT[:,i]为K矩阵的第i列向量,O[k,:]为输出O矩阵的第k行,V[i,:]为V矩阵的第i行,oi=∑j=1ipjV[j,:]为分片输出。
for i = 1, N do
ximili=Q[k,:]KT[:,i]=max(mi−1,xi)=li−1emi−1−mi+exi−mi
end
for i = 1, N do
pioi=softmax(x)=lNexi−mN=oi−1+piV[i,:]
end
O[k,:]=oN
第二个循环依赖了mN和lN,因为mN需要等第一个循环结束才能得到,所以无法直接合并两个循环。但是我们可以借鉴softmax迭代的技巧,实现o的迭代。
oi=j=1∑iliexj−miV[j,:]=j=1∑i−1liexj−miV[j,:]+liexi−miV[j,:]=(j=1∑i−1li−1exj−mi−1lili−1emi−1−miV[j,:])+liexi−miV[j,:]=oi−1lili−1emi−1−mi+liexi−miV[j,:]
优化后的公式只依赖li,li−1,mi,mi−1,li,因此我们可以合并两个循环。
for i = 1, N do
ximilioi=Q[k,:]KT[:,i]=max(mi−1,xi)=li−1emi−1−mi+exi−mi=oi−1lili−1emi−1−mi+liexi−miV[j,:]
end
O[k,:]=oN
最终我们省去了S和P,又因为xi,mi,li,oi因为占用空间足够小,所以可以放入GPU的共享内存。共享内存的速度比显存高出一个数量级。


重计算
在前向传播中我们省去了S和P,但是反向传播中需要使用S和P,通过在前向传播中引入的m和l,再加上输入Q,K,V,我们可以重新计算得到S和P。
反向传播中,设ϕ为损失函数,输出梯度dO=∂O∂ϕ∈RN×d,需要计算输入梯度dQ,dK,dV∈RN×d。
qi和kj分别表示Q的第i个块和K的第j个块,定义:
Li=j∑eqikjT
vj表示V的第j个块,则第i个块的输出:
oi=Pi:V=j∑Pijvj=j∑LieqikjTvj
dP和dV比较简单,可以直接得出,因为dV=PTdO,可得:
dvj=i∑Pijoi=i∑LieqikjTdoi
因为dP=dOVT,可得:
dPij=doivjT
dQ和dK比较复杂,我们先计算dS。因为Pi:=softmax(Si:),可以得到以下两个公式:
- ∂si:∂ϕ=∂p∂ϕ∂s∂p=dpi:(diag(pi:)−pi:Tpi:)
- ∂sij∂ϕ=pij(dpij−∑jpijdpij)
pdp的空间复杂度是O(N2),可能无法一次写入显卡的共享内存,所以论文通过一系列转换将空间复杂度减少到O(d2)(通常N≫d,如N是1K、2K,d是64、128)。
dSi:DidSi:dSij=dPi:(diag(Pi:)−Pi:TPi:)=Pi:⊙dPi:−(dPi:Pi:T)Pi:=dPi:Pi:T=j∑doivjTj∑LieqikjT=doij∑vjTLieqikjT=doij∑(LieqikjTvj)T=doioiT=Pi:⊙dPi:−DiPi:=PijdPij−PijDi=Pij(dPij−Di)
有了Sij,我们可以算出dQ和dK:
dqidkj=j∑dSijkj=i∑dSijTqi

FlashAttention2
FlashAttention2在FlashAttention的基础上优化了3点:
- 算法优化,包括前向和反向传播
- 并行化
- warp之间的工作划分
算法
论文举了一个例子,A100的GPU在执行矩阵操作时的吞吐量理论峰值是312TFLOPs/s,而非矩阵操作的吞吐量是19.5TFLOPs/s。换句话说,非矩阵操作的成本相当于矩阵操作的16倍。所以要尽可能减少非矩阵操作。
前向传播
为了减少非矩阵操作做了2点小调整。
计算注意力输出时,在循环过程中没有必要每次都缩放,而是在最后一步缩放。
不需要再保存为了反向传播重计算用到的m和l,而是保存logsumexp L=m+log(l)。(为什么是这个形式在后面的反向传播里解释)
优化后的算法伪代码:
for i = 1, N do
ximilioi=Q[k,:]KT[:,i]=max(mi−1,xi)=li−1emi−1−mi+exi−mi=oi−1li−1emi−1−mi+exi−miV[j,:]
end
LN=mN+log(lN)
O[k,:]=lNoN
反向传播
使用前向传播保存的logsumexp代替原先的m和l。
Pi=eSij−Li=eSij−mi−log(li)=lieSij−mi
经过转换后的P和原先的P相同。
并行化
在FlashAttention中的并行化是基于batch size和注意力头数量。总共需要的线程数是batch size和注意力头数的乘积。当这个数值足够大时,显卡资源利用率是高效的。但是当遇到长seqlen场景时,通常来说batch size和注意力头的数量会小的多,显卡资源的利用率就会降低。这时候就需要对seqlen维度做并行化。
前向传播
FlashAttention中的内层循环对Oi,mi,li进行重复读写,为了减少IO访问,可以交换内外层循环的顺序。
反向传播
反向传播维持原样,不需要做调整。因为如果交换了内外层循环,会导致需要通信的变量会增加,从原来的dQ变成dK和dV。
总结,前向传播是以行方向的seqlen做并行,反向传播是以列方向的seqlen做并行。
warp之间的工作划分
先介绍一下什么是warp,在 NVIDIA 的 CUDA 架构中,warp 是由 32 个并行线程组成的执行单元。所有这 32 个线程同时执行相同的指令(SIMT,即单指令多线程),但是它们可以操作不同的数据。通常1个线程有4个或者8个warps。
从论文中的解释可以发现本质是因为第二点的并行化优化减少了IO操作,所以不多做解释。
参考