# 前言
一般来说我们平时训练时使用的是32位浮点数(以下简称FP32),但是FP32占用内存较高,如果你的显卡的显存不够大就无法训练了,这时候可以用到量化(Quantization),将FP32压缩到FP16或者FP8以减少内存占用。QLoRA是目前比较流行的量化微调技术,它由微软在23年提出。在阅读了其相关的资料后,接下来分析一下它的核心算法。
# LoRA
在分析QLoRA之前,先介绍一下它的上一代技术LoRA(low rank adaption),它是在21年被提出,相比QLoRA,它没有用到量化,但是在微调时也能减少大量内存占用。
在当时微调大模型时,如果你有多个下游任务可能要存储多个微调后的模型,因为基础模型比较大,导致存储需要大量的空间,每次微调会更新全量参数,耗费大量时间。
LoRA提出冻结预训练参数,只训练增量参数的形式。有点类似代码工程里的组件仓库,我们的工程项目一般只会使用一套框架,如果每个项目都把框架代码一起提交会使代码仓库变大,也会影响后续框架的维护。这时候就需要把框架抽成组件单独维护。同理,我们只需要存储一份预训练模型,再额外存储每个下游任务微调后的参数即可。同时,LoRA引入低秩分解,将微调参数的矩阵分解为更小的两个矩阵,减少大量训练参数。因为作者相信并假设重要的特征信息分布在低秩子空间中,在后续的实验中也证实了这个想法。LoRA的含义就是在预训练权重旁引入低秩适配器,把预训练权重和适配器权重相加就是最后的权重。
上式中h和x是线性层,是预训练权重,是增量权重,低秩分解为。,,秩。假设d=1000,k=1000,r=8,可训练参数减少了近99%。
# QLoRA
QLoRA提出了3项量化技巧,分别是NF4、二次量化、分页优化。
# 4-bit NormalFloat Quantization
在介绍NF4之前先介绍一下量化,量化是指将模型的权重从浮点数转换为整数的过程。比如从32位浮点数转换为8位整数,这样可以减少75%的存储空间,还可以加速推理。副作用则是造成精度损失进而可能导致模型推理性能下降。
以下是从32位浮点数转换为8位整数的量化和反量化公式,8位整数范围[-128,127]:
上式中的c指的是量化常数或者量化比例。
这个方法的缺陷是如果输入向量里出现一个特别大的值,会导致数据量化后分布不均匀,进而导致更多的精度损失。解决这个问题的办法是将输入向量分块,每块独立量化,都有各自的量化常数,这样可以把异常值控制在一部分区间里。
NormalFloat4量化就是基于分块量化并使用NormalFloat4数据类型。那么它是如何充分利用16个位数呢?由于预训练神经网络权重通常符合零中心的正态分布,于是我们可以在正态分布上划分16个区间,每个区间的面积相等,设置范围[-1,1],将分位数和权重都做归一化。这里的分位数指的是每个区间的中点。
那么具体的16个分位数是如何计算的呢?如果按等比例划分16个区间,会导致没有零值,然而零值在权重里表示了特殊的含义,如果没有的话会导致原来为零的权重经过量化和反量化后无法回到零值,这就造成了很大的误差。所以论文里采用了非对称的划分方式,以0坐标为中心,左边取个分位数,右边取个分位数,左右合并后去掉重复的0点共16个分位数。但是这里有一个问题,因为-1和1是取不到的,如果使用norm.ppf计算分位数分别得到的是正无穷和nan,所以需要对范围做一下偏移。
论文中使用的是0.9677083,它的解释是左右两边的区间按中点(分位数)划分分别是15和16个半区间,各取半个求平均值,所以偏移量公式:
以下是NF4的量化和反量化过程:
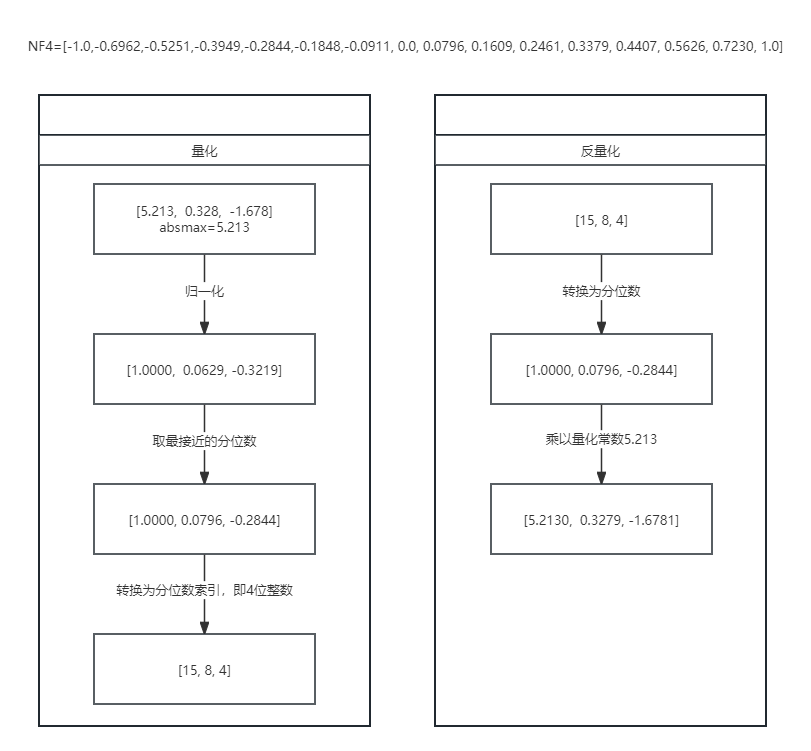
图中反量化后的值和量化前的值有误差,这就是量化后的精度损失。
# Double Quantization
在分块量化的基础上使用二次量化,例如每个块含有64个参数,每个块需要一个量化常数(32位),那么在未使用二次量化之前每个参数额外需要位。二次量化针对的就是额外增加的量化常数,量化到8位,论文中使用256个量化常数组成一个块,那么每个参数额外需要位,加起来额外总共需要位。二次量化节省了约75%的空间。
# Paged Optimizers
内存分页优化,利用了CUDA的统一内存特性,前提是需要显卡和CUDA版本支持。该特性在CPU和GPU之间进行自动页面传输,以确保在GPU偶尔内存不足的情况下进行无误的GPU处理。该特性类似于CPU RAM和磁盘之间的常规内存分页。我们利用此特性为优化器状态分配分页内存,当GPU内存不足时,这些状态会自动转移到CPU RAM 中,并在优化器更新步骤需要内存时分页回到GPU内存中。
def to_gpu(self):
for gindex, group in enumerate(self.param_groups):
for pindex, p in enumerate(group["params"]):
if p in self.state:
values = self.state[p]
for k, v in values.items():
if isinstance(v, torch.Tensor):
is_paged = getattr(v, "is_paged", False)
if not is_paged:
self.state[p][k] = v.to(p.device)
如果开启分页优化,tensor将不会被显示传输到指定设备,交由CUDA自动管理。
for gindex, group in enumerate(self.param_groups):
for pindex, p in enumerate(group["params"]):
if p.grad is None:
continue
state = self.state[p]
if len(state) == 0:
self.init_state(group, p, gindex, pindex)
self.prefetch_state(p)
self.update_step(group, p, gindex, pindex)
torch.cuda.synchronize()
def prefetch_state(self, p):
if self.is_paged:
state = self.state[p]
s1 = state["state1"]
is_paged = getattr(s1, "is_paged", False)
if is_paged:
F.prefetch_tensor(state["state1"])
if "state2" in state:
F.prefetch_tensor(state["state2"])
在执行优化器步骤之前对内存预调用。
def prefetch_tensor(A, to_cpu=False):
assert A.is_paged, "Only paged tensors can be prefetched!"
if to_cpu:
deviceid = -1
else:
deviceid = A.page_deviceid
num_bytes = dtype2bytes[A.dtype] * A.numel()
lib.cprefetch(get_ptr(A), ct.c_size_t(num_bytes), ct.c_int32(deviceid))
void cprefetch(void *ptr, size_t bytes, int device)
{
int hasPrefetch = 0;
CUDA_CHECK_RETURN(cudaDeviceGetAttribute(&hasPrefetch, cudaDevAttrConcurrentManagedAccess, device)); // 40ns overhead
if (hasPrefetch == 0) return;
CUDA_CHECK_RETURN(cudaMemPrefetchAsync(ptr, bytes, device, 0));
CUDA_CHECK_RETURN(cudaPeekAtLastError());
}
实际调用的是CUDA的接口,cudaMemPrefetchAsync 是 CUDA 提供的一个异步内存预取函数,用于在程序中显式地预取内存数据到 GPU 上,以加速后续对数据的访问。
整个流程是我们把内存交给CUDA管理,在优化器需要内存时,我们提示CUDA需要在GPU上用到多少内存,提前传输过去,加速后续访问。如果GPU内存吃紧,CUDA会自动把部分数据传输回CPU内存。